DeepSeek-OCR 论文解读
DeepSeek-OCR 论文解读
关键点
- “due to quadratic scaling with sequence length.” 是由于Attention机制本身导致的。
- “rather than basic VQA [12, 16, 24, 32, 41]” 这是训练OCR普遍使用的一种方式
- 主要的三个贡献
- 定量分析本文视觉压缩
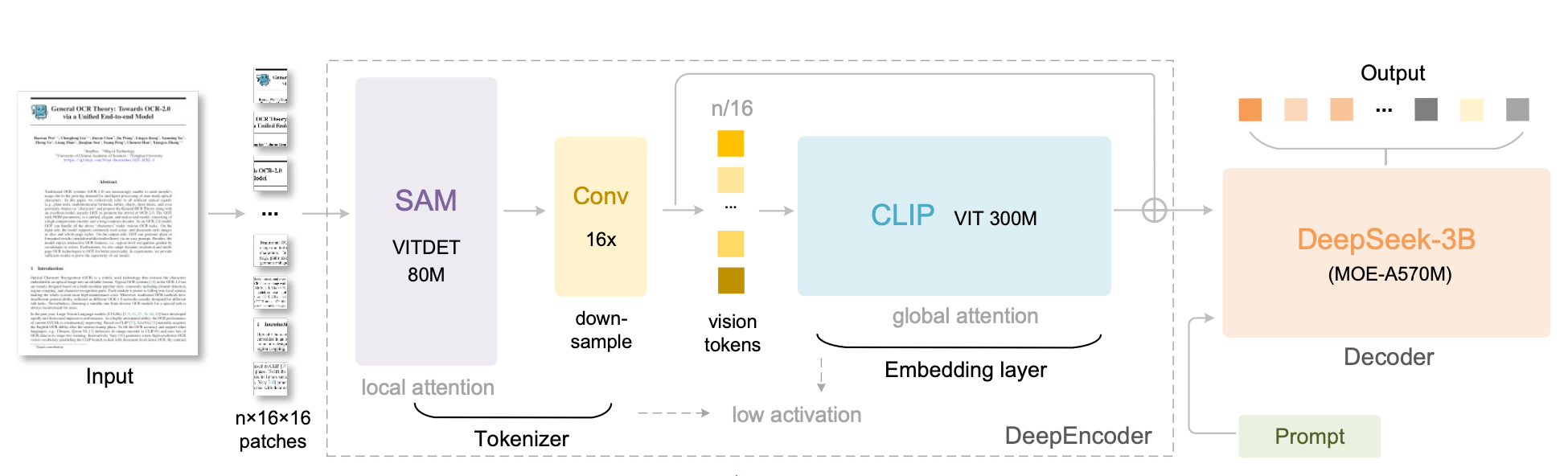
- 设计DeepEncoder模块
- 端到端模型构建与训练
- “offering a promising direction for addressing long-context challenges in large language models. " 能够在LLM的长上下文问题中提供一定的可行性
- 模型结构

- 数据
- OCR(1.0和2.0)70%
- 通用视觉数据(目标检测等)20%
- 纯文本(文本token信息)10%
- HAI-LLM 自己的模型训练平台框架,并行策略和算子优化
- 对比、效果、实验、评估