讲一讲word或者docx文档吧
最近线上项目解析docx文档遇到了很多问题,整体上记录一下这块内容吧。
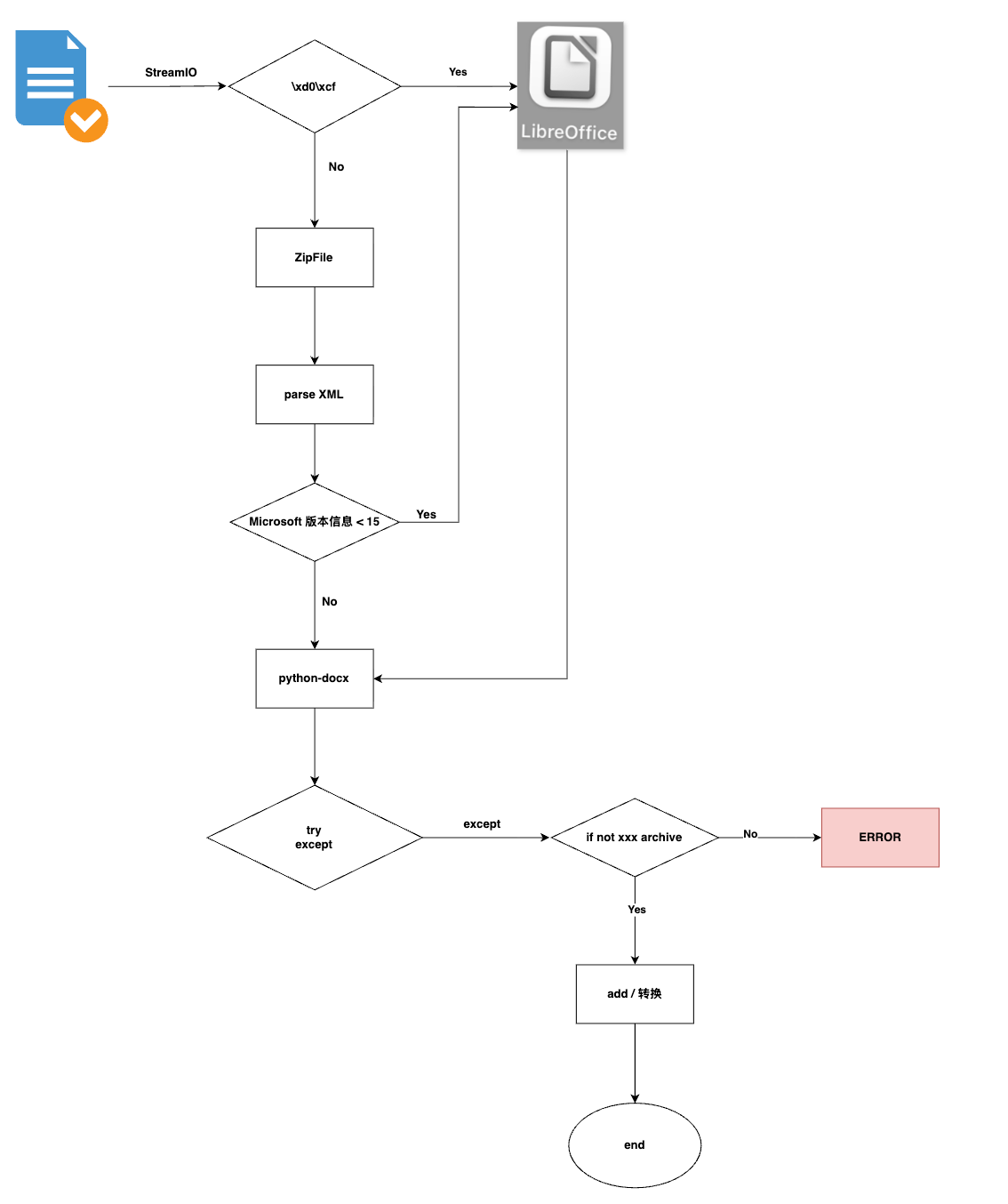
新版本(2007版本以后)的docx文件本质上是一种xml格式的标记文件,也相当于一种压缩文件,但是旧版本word97-2003是一种二进制文件,不是open xml规范。
使用python-docx解析docx文档时候的一些错误
File is not a zip fileThere is no item named 'xxx/xxxx.xml' in the archive- doc转docx后部分图片丢失
第一个问题File is not a zip file一般是由于当前的docx/doc版本比较旧,因为在word97-2003版本没有采用标准的Open XML规范,而是采用一种自己私有的OLE 2规范,本质上是一种二进制文件,也无法使用ZipFile打开,所以更不能使用python的python-docx打开或者解析。
Open XML 是一种基于 XML 和 ZIP 压缩的开放标准(由 ECMA 和 ISO/IEC 标准化,如 ISO/IEC 29500)。
那如何解决这一个问题呢,其实通用的办法就是采用LibreOffice将其转换成规范的docx文件,也就是open XML的docx文件,然后正常读取docx文件即可。
至于第二个问题,一般是非微软的word(比如Wps、Apache等厂商),另外就是这个docx版本符合open xml规范,但是还是跟进现在的规范,也就是在中间的一些版本(15以下的版本)缺失了一些archive,这个解决的话可以有几种办法:
- 直接以xml方式打开文件,然后删除对应的archive,比如:‘word/footnotes.xml’,但是我不推荐这样做。
- 第二种方式就是在代码打开解析的时候,当遇到这种标记或者标签的时候,对报错(
There is no item named 'xxx/xxxx.xml' in the archive)的标记进行跳过或者添加相关标记,这种方式倒是可以,就是需要有一定的理解能力。 - 第三种方式更为通用。直接使用
LibreOffice转换,一般不会出现什么问题。
这些都是我在排查一些线上问题的时候琢磨的东西,如果有不对的地方还希望读者能够提出来,另外的话对于这些代码,我其实是专门有存放的: docx_process ,大家可以作为参考。
其实还有很多细节,比如文件用字节流打开的时候,如果前面的字符流就能体现出它的规范,b'\xD0\xCF\x11\xE0\xA1\xB1\x1A\xE1'开头的就是word97-2003的,b'PK\x03\x04'就是xml规范的,整体上的修复逻辑大致是这样子的: