LLM4Rec-Learning-002: 大模型推荐的Pipline
本节是大模型LLM4Rec的Pipline,从论文、数据到源码一步步进行探索 围绕“TIGER”论文展开
主要内容
- 谷歌2023年的论文“TIGER”
- Recommender Systems with Generative Retrieval
- VQ-VAE & RQ-VAE
- https://github.com/EdoardoBotta/RQ-VAE-Recommender
- Amazon数据集
论文解读
整体结构
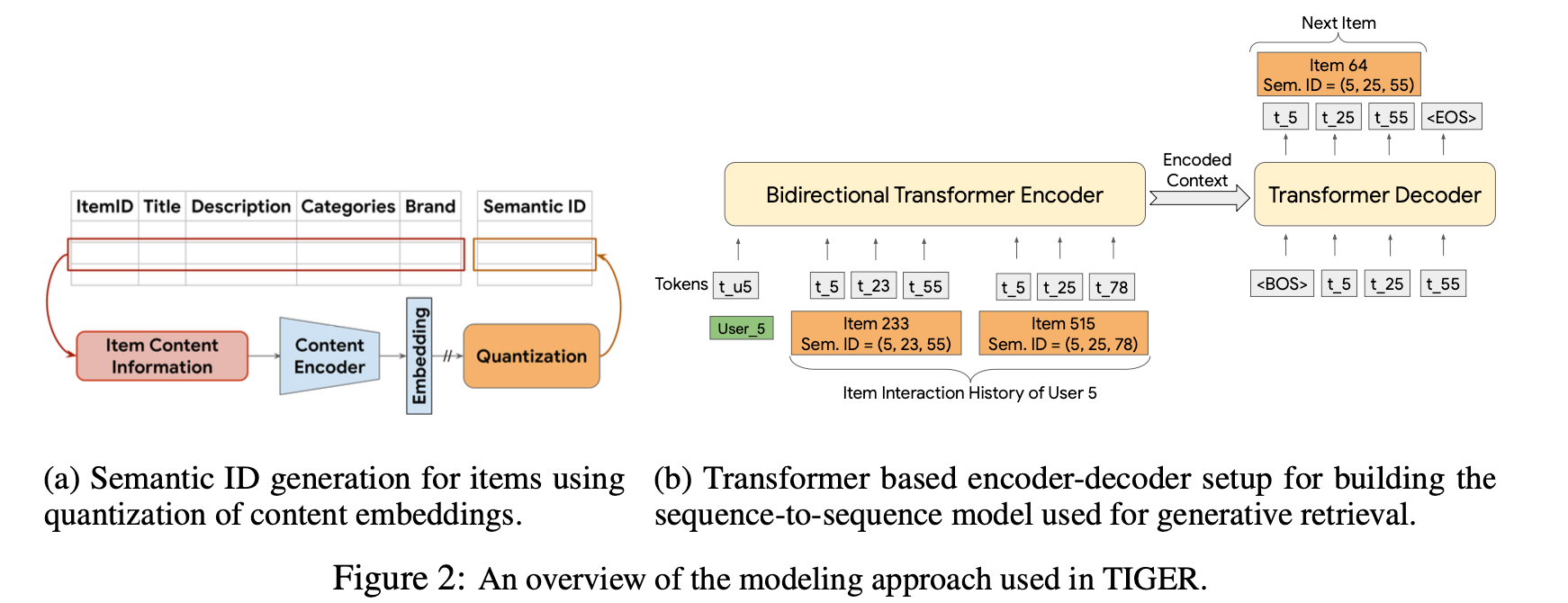
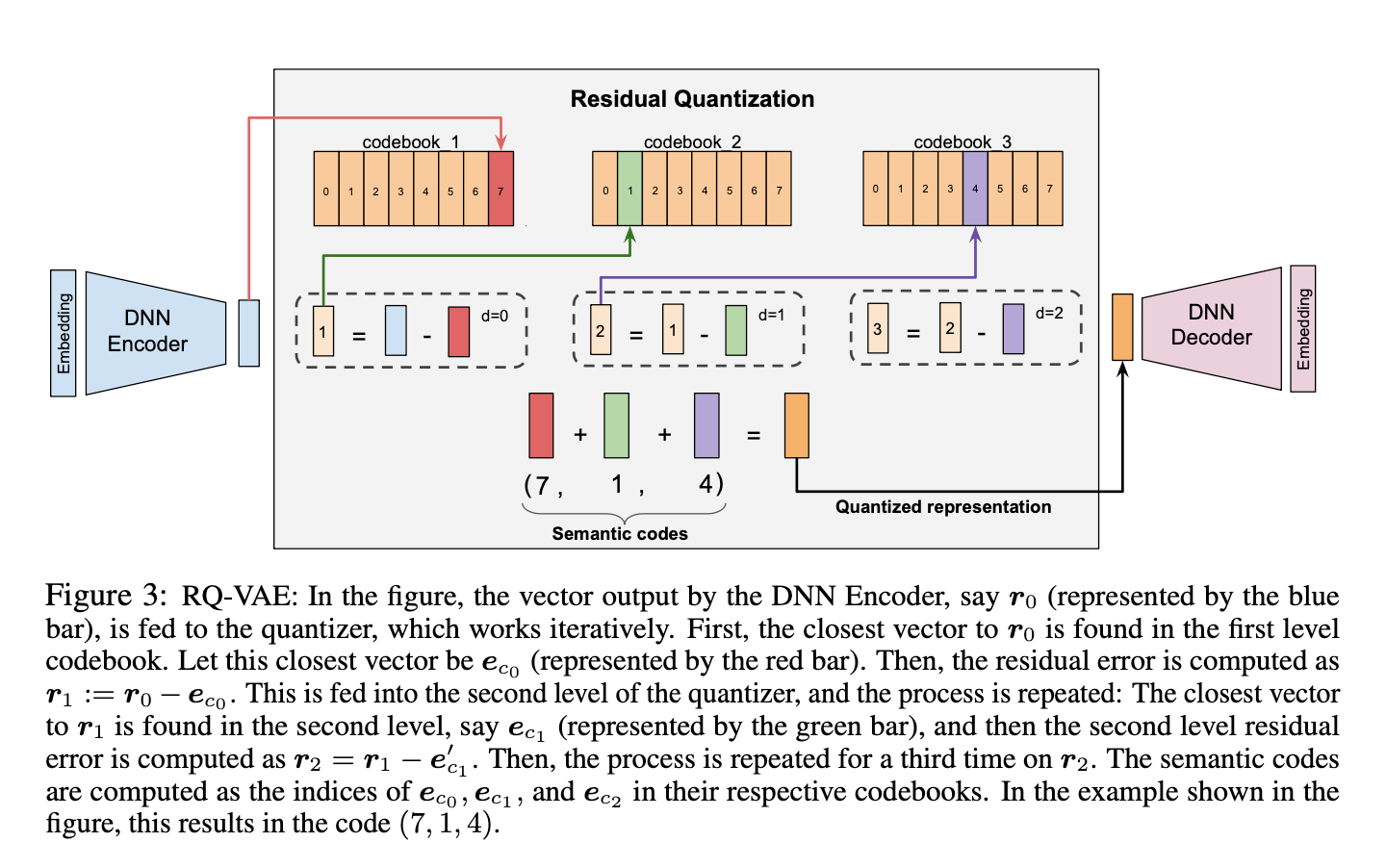
RQ-VAE量化
📌 检索不再发生在向量空间 📌 而发生在“token 空间”
量化的其他选项
- 局部敏感哈希(LSH)
- VQ-VAE
- RQ-VAE
数据集
Datasets. We evaluate the proposed framework on three public real-world benchmarks from the
Amazon Product Reviews dataset[10], containing user reviews and item metadata from May 1996
to July 2014. In particular, we use three categories of the Amazon Product Reviews dataset for the
sequential recommendation task: “Beauty”, “Sports and Outdoors”, and “Toys and Games”. We
discuss the dataset statistics and pre-processing in Appendix C.
思考
user/item 进行embedding后进行量化,是在干什么?为什么这样做?目标?
各个模块和整体模块的输入输出是什么?长啥样?