LLM4Rec-Learning-002: 生成式推荐的Pipline——TIGER
本节是LLM4Rec的Pipline,从论文、数据到源码一步步进行探索 围绕“TIGER”论文展开
主要内容
- 谷歌2023年的论文“TIGER”
- Recommender Systems with Generative Retrieval
- VQ-VAE & RQ-VAE
- https://github.com/EdoardoBotta/RQ-VAE-Recommender
- Amazon数据集
论文解读
相关术语
- Codebook:码本,所有 codewords 的集合,shape codebook_size × embed_dim 。
- Codeword:码字,码本的一行向量,代表一个离散原型。
- Quantize(量化):将连续向量 x 映射到最接近的 codeword 并输出其索引 ids 与嵌入 embeddings 。
- Residual(残差):当前编码向量减去选中的码字嵌入,传给下一层量化。
- Commitment loss:约束 x 贴近 embeddings 的损失,促进一致性。
- Gumbel-Softmax:对 logits 做带噪 softmax 抽样,得到平滑的码字加权向量,有利于端到端训练。
- Rotation Trick:用旋转变换降低量化误差的前向策略。
整体结构
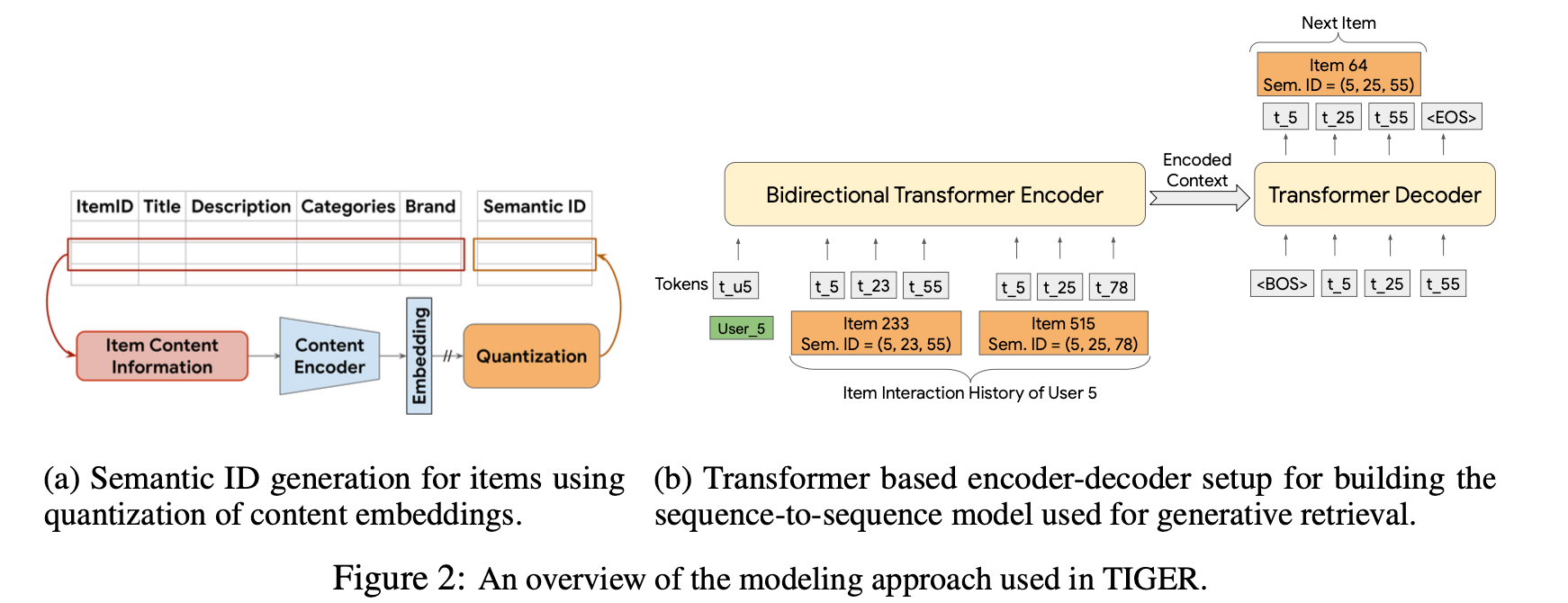
RQ-VAE量化
想想这块主要是在干啥?以及为啥这样做?
📌 检索不再发生在向量空间
📌 而发生在“token 空间”
量化的其他选项
首先我们需要明确一点(整体上有感觉),这个模块主要是解决什么问题?是在干啥?大致的策略是怎样的?
这些算法,本质上都是在“处理大量高维数据”, 让我们能 **更快地找相似东西,或 更高效地表示、压缩、生成数据。
局部敏感哈希(LSH)
有 1 亿个向量(比如用户画像、商品特征、文本 embedding), 现在来了一个新向量,想找 最像它的那几个。主要是召回层
LSH的策略就是: 不用一个个去比,而是先“分桶”,把“相似的向量”大概率分到同一个桶,只在少数桶里找。主要是为了能够快速实现相似匹配检索
结构:[ 向量 ] → LSH → 候选集合 → 精排
VAE
VAE:主要就是把复杂数据 (一张图片、一个语音、一个用户行为序列存在关联性)压缩成一小段连续的数字(潜在表示),同时还能够从这些数字再生成回原始数据;另外,他还有一个关键点就是能够“可生成、可插值”的表示。主要是表征层
结构:[ 原始数据 ] → [ Encoder ] → [ 连续潜变量 z ] → [ Decoder ] → [ 重构 / 生成 ]
VQ-VAE
VQ-VAE:把连续数据(比如Embedding)映射成有限个离散编号,想想为啥这样做?主要是表征层
结构:[ Encoder ] → [ 连续向量 ] → [ 查码本 → 离散ID ] → [ Decoder ]
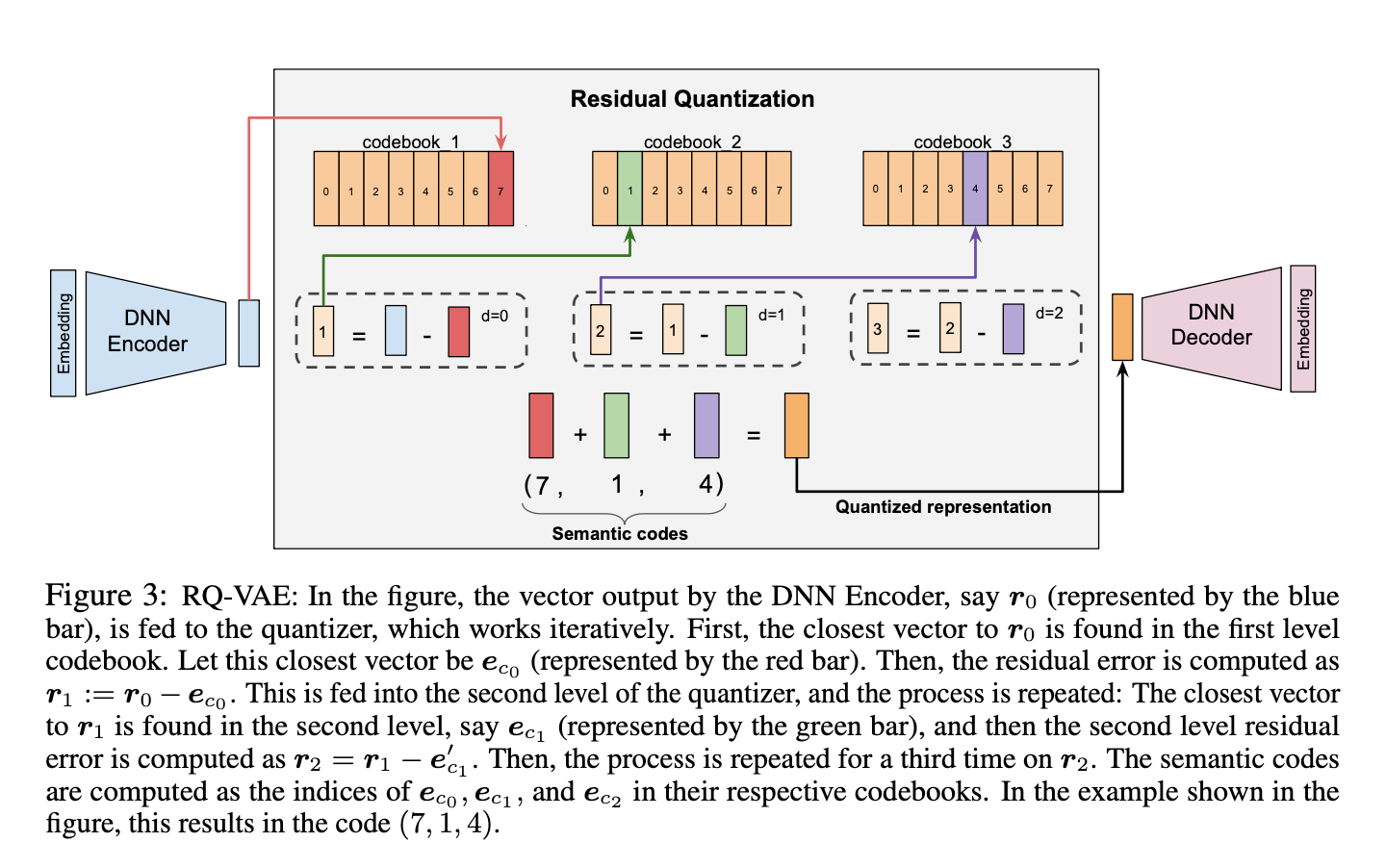
RQ-VAE
RQ-VAE:算是VQ-VAE的优化,主要是表征层
结构:[ Encoder ] → [ 残差量化 × 多层 ] → [ 多个离散ID ] → [ Decoder / 检索 ]
数据集
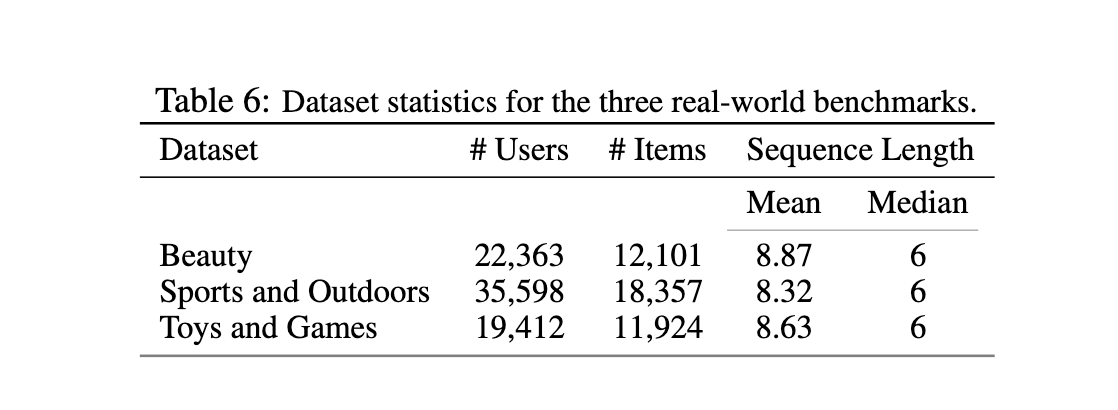
Datasets. We evaluate the proposed framework on three public real-world benchmarks from the Amazon Product Reviews dataset[10], containing user reviews and item metadata from May 1996 to July 2014. In particular, we use three categories of the Amazon Product Reviews dataset for the sequential recommendation task: “Beauty”, “Sports and Outdoors”, and “Toys and Games”. We discuss the dataset statistics and pre-processing in Appendix C.
源码跑通
源码的README写的比较清晰了,整体上是两个阶段,阶段一是表征学习,阶段二是生成式推荐学习
由于阶段一作者用的T5模型,5b左右,我设备带不起来,我就换成一个很小的0.1b的模型了,维度从原来的768变为384了,所以对应的几个输入维度也要修改为384,另外就是发现训练时候效果很差,个人猜测是vae_hidden_dims还是之前的隐藏层维度,有点太复杂了,然后我调整了一下,参数自己调了好几类,最后大致 锁定在了一个范围,也是效果不错的了,后面进行第二个步骤。
阶段一结果:
| |
指标(Amazon 阶段一):
- reconstruction_loss 越低越好,表示码字组合能重构原始向量。
- rqvae_loss 合理的量级即可,过大说明 x 与码字距离大;可调 commitment_weight 。
- codebook_usage_* 接近 1 表示码本使用均匀;过低表示容量过大或训练不足。
- rqvae_entropy 越高越均匀;过低表示语义ID集中于少数组合。
- max_id_duplicates 越低越好;过高说明不同物品映射到了相同语义ID。
第二阶段也类似,不过是通过生成式的策略,暂时先跑通代码,有点脑雾的感觉,后面分析梳理第二阶段
思考
user/item 进行embedding后进行量化,是在干什么?为什么这样做?目标?
各个模块和整体模块的输入输出是什么?长啥样?