毕业论文Ideas: 推荐系统同质化问题
毕业论文Ideas: 推荐系统同质化问题
自己本心是很喜欢探索和研究的,而且很享受那种感觉,事实上,真正尝试做的情况很少很少,很多都是有念头和想法,于是始终有一颗读研的打算(前提是得先考得上),但自己综合考虑之后是选择了先就业(打工)的,于是在选择后尽管自己很坚定,但始终有一个执念在我心头——研究,以至于在多次实习的时候,总是心头想着有个读研的打算,现在毕业论文其实就是一项真正的“研究”,他不同与我之前参加的一些竞赛,这种自我探索远比那些带着方向性的考验性更强,所以,这是让我的那个执念得以一定量放下的最好机会,至于以后是否有考研打算,顺势而为即可,至少,心中那颗心总算可以放一放了,那接下来,我就是慢慢做,做到自己以前想的那样种感觉,不能说要做的多么高大上、多么新颖,而且有一颗认真科研的心,探索里面的乐趣。Let’s Go!
keywords
- Information Cocoon(信息茧房)
- Homophily(同质化)
- Filter Bubble(过滤气泡)
- Preference Drift(偏好漂移)
- Personalization Loop(个性化闭环)
- Algorithmic Bias(算法偏见)
- Echo Chamber(回音壁 / 回声室)
Thinks
多样性推荐
挖掘数据潜在的特性
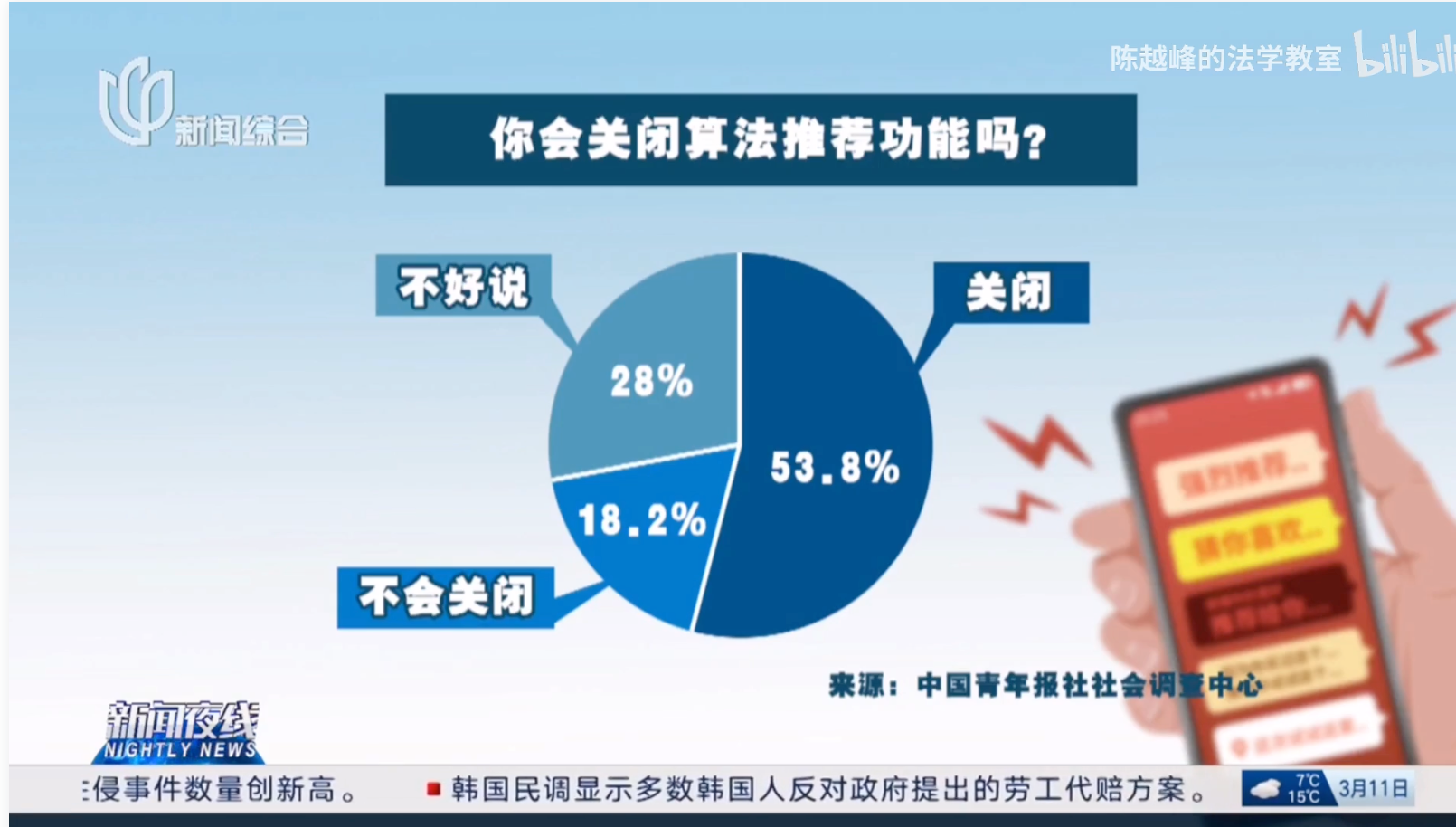
各个平台越看越窄(网友相关内容和评论截图与统计)
抖音、快手、b站、视频号;小红书;淘宝、pdd;公众号;微信读书;播客app;
人们几乎是离不开这些了
之前专门出门观察过行人,除去骑车的和多人同行的,剩下的基本就是单人行走的人群,这群人当中,90%以上的是边走边刷手机的。
社交、购物、短视频、知识平台
内容雷同度阈值特别高的不推荐召回
依据平台的特点做阈值过滤(比如小红书的封面+文字+文案,雷同过高,比如抖音的文案和时常)
除了专门搜索,其余重复推荐率调到5%
被“标签”化、tag
人是喜欢新鲜感的,“人们喜欢怎样的?”
当然,单一的“搜索”也要多样化一点
“小红书评论有很多一样,满屏”
美化,“真实”-美好,人的反思是不足的
“真实生活的记录”
中国互联网络信息中心:提供中国互联网络发展状况统计数据等。
基于内容的推荐
title“推荐并不仅仅是指标,去同质化,多样化推荐的必选项”
普适性推荐,而不是信息茧房、马太效应、
信息化,各方面信息,但是自己专业领域,希望有更深的内容
生成式多样化推荐系统
社会良好发展、长期健康运行的必要举措
先抛出几个问题(xxx,xxx)
抖音(or others)后台的作品不同类别下面随机选不同时段不同周期的不同类型视频内容
探究其向量化后的向量空间分布
然后看看用户侧(民大学生和我周围的学生)的数据(已看完、已点赞或收藏、已分享、已评论的)
基于种子用户群去使用大模型进行潜在用户推荐
焦虑的(感情、工作、家庭)、负面新闻的、happy、搞笑和反差的等等等
多样性+多数的高质量的、安详的、真实人间烟火、都不是完美的
多样化子用户群
具有潜在相似但实际是多样的(潜在的,比如有类似的策略)
冷启动和长尾问题
探究心理因素
阶段性历史交互数据
潜在tag,然后构造多样化推荐(同时又带有相关性)
同时要不缺乏原有的的个性化推荐
不仅仅是items侧考虑多样性,也可以是user侧做到多样
以前推荐算法提高准确是因为想在海量数据里面快速并尽可能地匹配到相关的内容进行推荐,但现在这块已经做的够好了,以至于用户侧陷入到了一种“精准化”推荐,这在现在看来并不友好,物极必反,提高兴趣推荐的同时,更应该考虑用户侧的身心健康,现在更应该考虑的是“兴趣推荐+多样化”,因为用户对于自己需要的东西会进行相关的查询搜索,但这不是让尽可能地推荐搜索的内容。所有路走着走着似乎走错了,做算法的也陷入到了自己的“信息茧房”
现在(可能):重排的多样、业务后的多样,前处理方法、中处理方法和后处理方法

papers
- ✅小红书-2025-10 HyMiRec: A Hybrid Multi-interest Learning Framework for LLM-based Sequential Recommendation
- ✅小红书-2025-10[RED-Rec: CROSS-SCENARIO UNIFIED MODELING OF USER INTERESTS AT BILLION SCALE]
亚马逊-2025-06 Large Language Model-Enhanced Reinforcement Learning for Diverse and Novel Recommendations
淘宝-2025-02 Bursting Filter Bubble: Enhancing Serendipity Recommendations with Aligned Large Language Models
2025-02 Fairness and Diversity in Recommender Systems: A Survey
v1-v4: Result Diversification in Search and Recommendation: A Survey
v1-v2 Fairness and Diversity in Recommender Systems: A Survey
2022 推荐系统的多样性总结
如何读论文
顶会:KDD、SIGIR、WWW、CIKM、IJCAI、RecSys、NeurlPS 一、方法整体流程 第一步:收集并整合相关资源 第二步:深入研究你认为与主题相关的任何资源 第三步:做笔记,对该领域理解的升华 二、详细阐述如何阅读一篇论文 第一遍:阅读标题、摘要、文中图表 第二遍:阅读引言、结论,掌握关键信息;并结合图表快速扫描文章其余的内容 第三遍:对论文进行整体阅读,但要跳过任何对你来说可能陌生的复杂的数学或技术公式。在此过程中,还可以跳过不理解或不熟悉的任何术语和术语 三、通过问自己问题来检测对论文的理解程度 1、论文的作者想要完成什么,或者已经完成了什么? 2、如果一篇论文介绍了一种新方法/技术/方法,那么该新方法的关键要素是什么? 3、论文中哪些内容对你有用? 4、你还想关注哪些参考文献?
知网硕士论文: 面向用户多层次多样化推荐的端到端学习框架
future
不足、展望
- 后反馈和优化(RL)
- 数据选择的局限性,但是依旧能表明此现象
- 当然,我想到的这些基本人人都知道,他们的算法团队也依旧知道,至少任免陷入其中,活在一个局部小世界里,很难再出来了
- 我写的并不是好的,但是是一个值得思考的问题,也是我觉得社会长期较为健康发展、平台能够长期生存的重要项。
- 长尾数据?
- 缺乏真实的线上用户测试
- “感觉一个重要的生态是能让短视频推荐如此内卷的情况下,脱颖而出的关键。比如微信的社交属性,xhs的经验分享贴,bilibili的学习长视频。这些不同于其他软件的属性,是让一个软件不断飞轮的关键,不然仅凭推荐算法工程师也难为没有稠密用户行为的无米之炊。”