生成式推荐量化——RQ-VAE
生成式推荐中的item特征空间量化方法:RQ-VAE
在生成式推荐中,现在主流的方案是类似如下方式【笔者绘制不一定完全正确】:
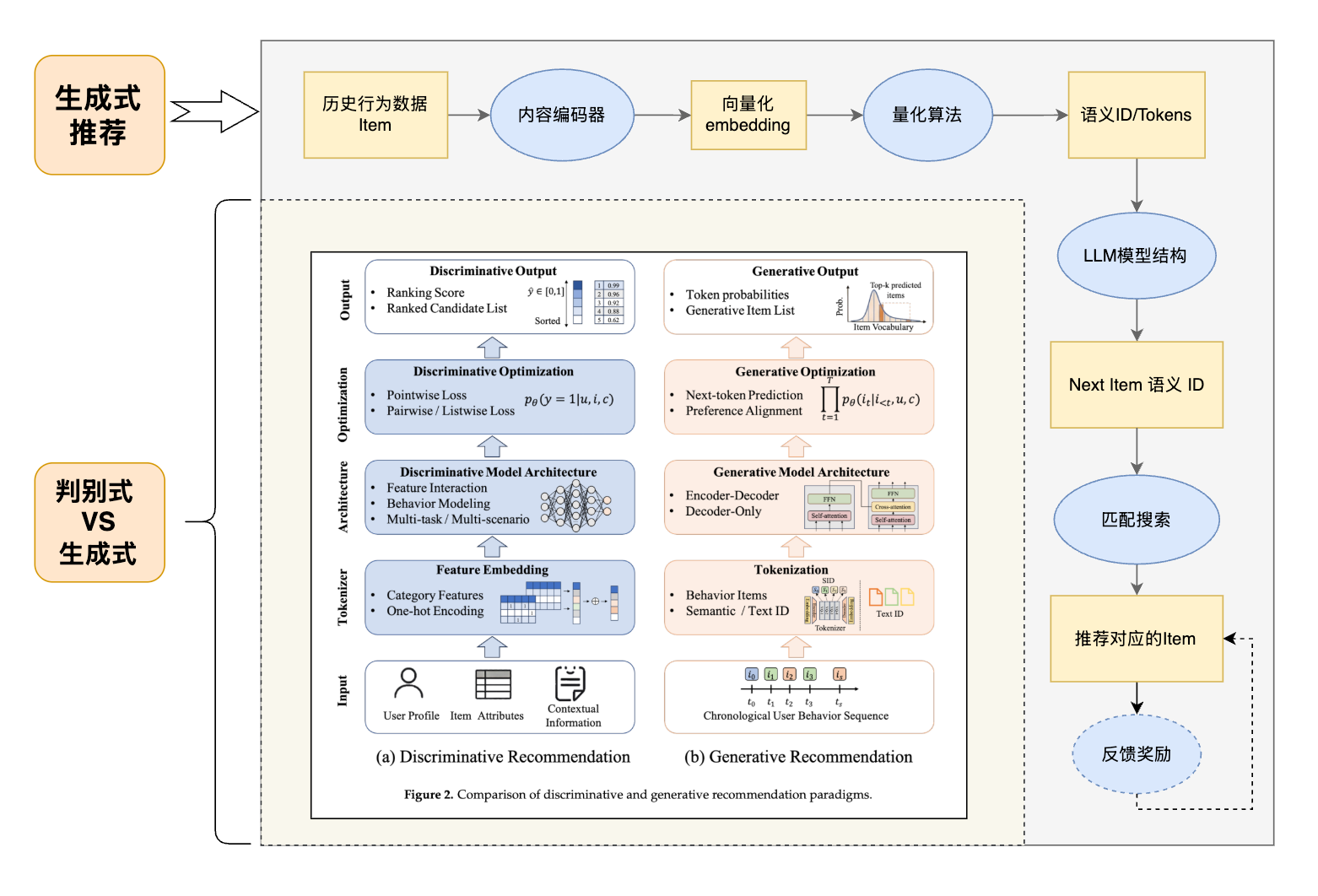
- 靠边框的流程为生成式推荐的基本流程
- 左下角是传统判别式推荐与生成式推荐的对比图
现在,需要深入学习一下其中的量化环节,以最典型的RQ-VAE算法进行讲解。
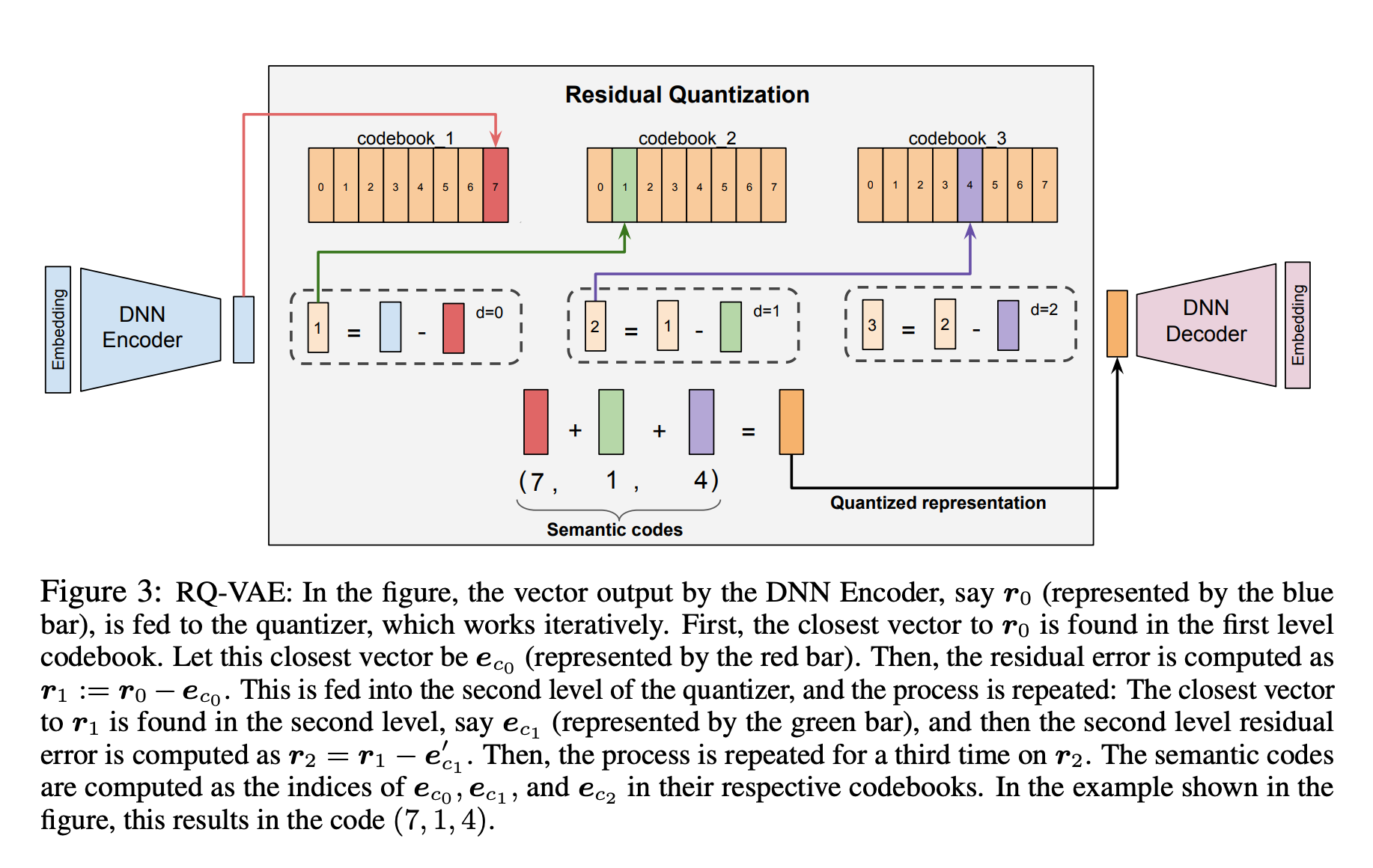
RQ-VAE模型由三个部分组成:一个DNN的Encoder,用于将输入的Semantic Embedding编码为latent Embedding示;一个残差量化器(residual quantizer),用于输出量化表示;以及一个DNN Decoder,用于将量化表示解码回语义输入Embedding。
- 将原始数据通过编码器构建Embedding向量空间,然后进行latent降维Embedding(比如: 1024->64)
- 进入到RA-VAE(残差量化)模块,会进行三层量化:
- 第一层是$r_0$:将latent的Embedding与codebook1中最匹配、最接近的codevector做残差,并得到对应最匹配的codevector的index,即Semantic ID。
- 第二层是$r_1$:将第一层残差向量结果$r_0$与当前codebook2中最匹配、最接近的codevector做残差,并得到对应最匹配的codevector的index,即Semantic ID。
- 第三层是$r_2$:同上,与codebook3中的匹配得残差,并得到index。
- 通过2得到当前输入数据对应的Semantic Code,即$(i_1, i_2, i_3)$,为保障唯一性或者防止碰撞,即“僧多粥少”现象,会额外多加一位,得到$(i_1, i_2, i_3, i_{K+1})$,当然也有其他策略。
- 将history的窗口数据按照以上方式构建一条Semantic Tokens,然后利用Transformer架构构建生成式任务,预测一个个Semantic ID,然后一组Semantic IDs为Semantic Code,与item算是一一对应。
- 生成的Semantic IDs如何映射为item?流程:离散编码→连续向量→具体内容,逆向还原。这儿需要用到Codebook,用Semantic ID查到对应的code vector,然后通过解码得到对应的item Embedding。
RQ-VAE量化的损失计算(主要是得到对应的每一个codebook):

问题:
- 每个codebook的纬度和大小是否要一致?why?
- 如何理解残差的信息量递减?
- 这种量化与PCA还有t-SNE的降维方式有啥区别?
- codebook是怎么得到的?初始化呢?
- 解码流程是怎样的?
- 训练流程与更新?
- 想想为啥要这样做?这个必须吗?
- 如何理解该量化方案?
参考资料:
- 原始论文TIGER: Recommender Systems with Generative Retrieval
- 原始论文仓库代码: RQ-VAE-Recommender
待学习blog: